My Experience with Goole Cloud Firestore in Datastore Mode
- Vishakh Rameshan
- Dec 30, 2020
- 6 min read

Updated: Jan 30, 2021
Google Cloud Datastore which has now been deprecated and instead Firestore has been brought GA. This has 2 flavors/modes supported. One is native and other one is Datastore mode.
For one of my batch application I was using Cloud SQL to store metadata and job informations by doing CRUD operations using Cloud Dataflow. But due to Cloud SQL being a regional service and in case of High Availability during disaster time, having cross region replication was not enough for my project. Instead the decision was to test out Firestore capability, to see if we can leverage the multi regional Cloud Firestore service to handle processing needs which was done by Cloud SQL.
Having to take a sudden decision to replace a SQL database with a NoSQL database would definitely cause some challenge as this was my first encounter with a NoSQL DB. So I wanted to test its features of supporting CRUD operations using Dataflow by doing a Proof-of-Concept to showcase my findings.
I went through google documentation on Cloud Firestore and took steps to launch one in my Google Cloud Project. The first page that I saw was to decide the mode (native vs datastore) to be selected.
So understanding the difference between those was very important as once I select a mode and launch the instance, I cannot revert back, nor I can have another instance of Firestore in the same project.

So lets see the difference between those 2 and in which situation its better to choose
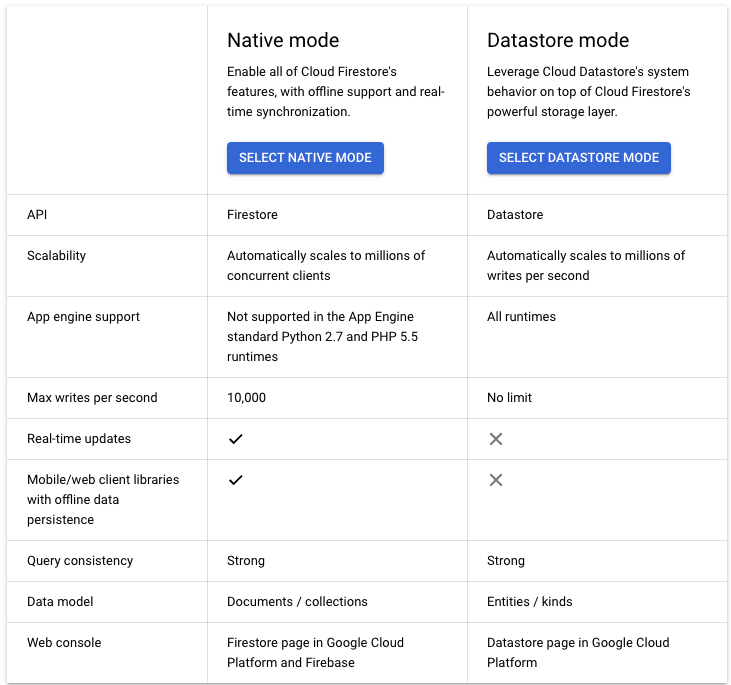
From the above differences it was clear for me to choose Datastore mode, as I do not need a real time update features and offline data persistence as the application does not have a mobile/web interface.
Next option in the setup page was to select the region and without any doubt I selected us multi region as the application is US specific. But an important warning here is that selection of region is also permanent.
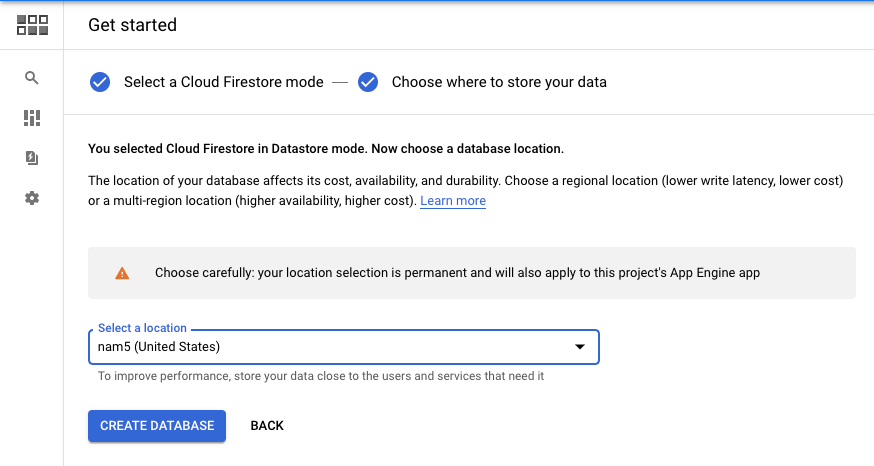
In the above picture you can see the warning and in thats it's mentioned something about App Engine. So it was clear that there was some dependency with the App Engine. To get a solid understanding on this I further investigated and found out that the Firestore in Datastore mode needs a default application to be running in App Engine. So when you setup Datastore automatically a default application will be deployed in App Engine, which does not actually effect any of the business nor there will be any cost.
The only problem here is that you should not disable the default application running in App Engine. But, you can deploy any additional application if you want to as a service in App Engine.

Don't get confused with the term application, service etc as these are App Engine jargons. To get a more clear idea, have a look at this page where I have documented my understanding.
Until the first entity is created, you still get a chance to switch the mode from datastore to native and vice versa

There can only be one Firestore instance (either native or datastore mode) in a GCP project, so even if you navigate to Firestore page or datastore page you would see as
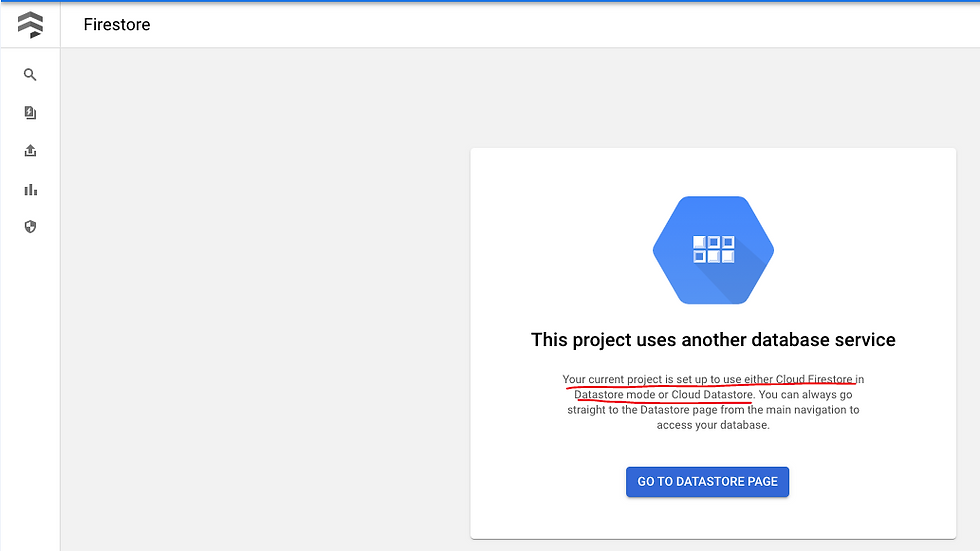
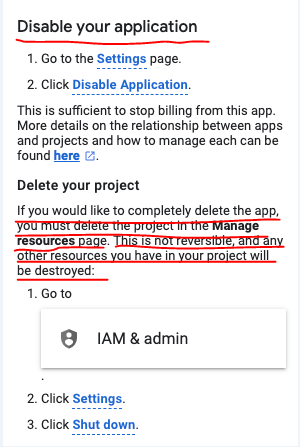
Even if App engine service is enabled and a default application is deployed, there won't be any cost issues nor it would stop you from deploying a new application as a service to App Engine. But in case you plan to delete the App Engine, beware that it's not possible. You can disable the default application, but you cannot delete it. The only way it's possible is to delete the entire GCP project.
Go to App Engine settings and you would see the disable application option.
Designing Entities
Entities are like tables in SQL and Namespace are like schema which separates multiple application running under same GCP project to consumer the single Datastore instance. Each entity will have properties which are columns in case of SQL.
While creating entities couple of points to remember
The primary key can be auto generated id or custom name. Auto generated ID is handled by Datastore by default and is a good option compared with custom name. Even if you choose custom name, it should be created in such a way that each entity(record) should be evenly distributed in datastore distributed nodes to avoid hot spotting (accumulating every records on same machine, thus increasing overhead and not using the full fledged feature of distributed computing architecture), as datastore is multi regional and data is distributed on multiple machines.
Avoid creating unique key (custom name) in a particular order like person1, person2... as this will lead to hotspotting
While creating property for an entity, there is an option to index each property so as to have the GQL (Datastore Query) faster. Indexing unwanted column will result in query performance degradation.
There are two types of indexes:
Built-in indexes By default, a Datastore mode database automatically predefines an index for each property of each entity kind. These single property indexes are suitable for simple types of queries.
Composite indexes Composite indexes index multiple property values per indexed entity. Composite indexes support complex queries and are defined in an index configuration file (index.yaml).
Columns used in a where clause of GQL must be indexed

Only Equality operator (=) in GQL where condition is not permitted for the column which is present both in select and where clause.

I my case like I mentioned I do not intensively use datastore and so my queries are very straight forward and simple. So having built in index was enough for me to perform my activities.
With this the entity creation was completed and now creating Dataflow pipeline to perform CRUD operation was the next task.
Roles Required



Dataflow Job - Perform CRUD operations
Driver class which sets the dataflow runtime args options and launching pipeline for each of the create, read, update and delete entity from datastore.
public static void main(String[] args) {
DatastoreOperationsOptions options = PipelineOptionsFactory.fromArgs(args).withValidation().as(DatastoreOperationsOptions.class);
Pipeline pipeline = Pipeline.create(options);
if ("create".equalsIgnoreCase(options.getDatastoreOperation()))
StarterPipeline.datastoreInsert(pipeline, options);
else if ("read".equalsIgnoreCase(options.getDatastoreOperation()))
StarterPipeline.datastoreReadAndGcsAvroWrite(pipeline, options);
else if ("update".equalsIgnoreCase(options.getDatastoreOperation()))
StarterPipeline.datastoreUpdate(pipeline, options);
else if ("delete".equalsIgnoreCase(options.getDatastoreOperation()))
StarterPipeline.datastoreDelete(pipeline, options);
pipeline.run();
}Create/Insert Entity
java -jar firestore-crud-demo-0.0.1-SNAPSHOT.jar \
--runner=DataflowRunner --project=my-project \
--region=us-east1 --zone=us-east1-b \
--jobName=insert-entity-datastore \
--serviceAccount=datastore-crud-demo.iam.gserviceaccount.com \
--subnetwork=https://www.googleapis.com/compute/v1/projects/my-project/regions/us-east1/subnetworks/my-sub-net-001 \
--usePublicIps=false --workerMachineType=n1-standard-1 \
--numWorkers=1 --maxNumWorkers=3 \
--tempLocation=gs://demo-bucket/firestore_crud_demo/temp \
--datastoreOperation=create \
--datastoreWriteProjectId=my-project \
--datastoreWriteNamespace=demo \
--datastoreWriteEntityKind=person \
--name=kevin \
--status=single \
--dob=19-05-1992 List<String> keyNames = Arrays.asList("L1"); // This is a mock key but not used anywhere, used to avoid syntax error
pipeline.apply("GetInMemory", Create.of(keyNames)).setCoder(StringUtf8Coder.of()).apply("CreateEntity",ParDo.of(new WriteEntity(options.getDatastoreWriteNamespace(), options.getDatastoreWriteEntityKind(), options.getProcessName(), options.getProcessStatus(), options.getStartDate(), options.getEndDate()))).apply("WriteToDatastore", DatastoreIO.v1().write().withProjectId(options.getDatastoreWriteProjectId()));public class WriteEntity extends DoFn<String, Entity> {
private static final long serialVersionUID = 100000786999L;
private String namespace;
private String kind;
private String name;
private String status;
private String dob;
public WriteEntity(String namespace, String kind, String name, String status, String dob) {
this.namespace = namespace;
this.kind = kind;
this.name = name;
this.status = status;
this.dob = dob;
}
@ProcessElement
public void processElement(ProcessContext c) {
Key.Builder key = makeKey(this.kind, Instant.now().toEpochMilli());
key.getPartitionIdBuilder().setNamespaceId(this.namespace);
Entity entity = Entity.newBuilder()
.setKey(key)
//name needs to be indexed as the update and delete operation need to be performed for this demo
.putProperties("name", makeValue(this.name).setExcludeFromIndexes(true).build())
.putProperties("status", makeValue(this.status).setExcludeFromIndexes(true).build())
.putProperties("dob", makeValue(this.dob).setExcludeFromIndexes(true).build())
.build();
c.output(entity);
}In the DoFn the key is calculated based on the current timestamp in epoch. As this generated long value is almost distinct, it will be evenly distributed. The generated key is set in the setKey method of datastore. Each property is added to the makeValue method with excluding and including that particular property from indexing.
Read/Select Entity
java -jar firestore-crud-demo-0.0.1-SNAPSHOT.jar \
--runner=DataflowRunner --project=my-project \
--region=us-east1 --zone=us-east1-b \
--jobName=read-entities-datastore-write-avro-gcs \
--serviceAccount=datastore-crud-demo.iam.gserviceaccount.com \
--subnetwork=https://www.googleapis.com/compute/v1/projects/my-project/regions/us-east1/subnetworks/my-sub-net-001 \
--usePublicIps=false --workerMachineType=n1-standard-1 --numWorkers=1 --maxNumWorkers=3 \
--tempLocation=gs://demo-bucket/firestore_crud_demo/temp \
--datastoreOperation=read \
--datastoreReadGqlQuery='select * from person' \
--datastoreReadProjectId=my-project \
--datastoreReadNamespace=demo \
--outputWritePath=gs://demo-bucket/firestore_crud_demo/personpipeline.apply("ReadFromDatastore", DatastoreIO.v1().read().withProjectId(options.getDatastoreReadProjectId()).withLiteralGqlQuery(options.getDatastoreReadGqlQuery()).withNamespace(options.getDatastoreReadNamespace())).apply("EntityToAvro", ParDo.of(new JsonToPojo()))
.setCoder(AvroCoder.of(Customer.class))
.apply("WriteToGCS", AvroIO.write(Customer.class).to(options.getOutputWritePath()).withSuffix(".avro"));public class JsonToPojo extends DoFn<Entity, Person> {
private static final long serialVersionUID = 100000786997L;
private static final String PROPERTIES_FIELD = "properties";
private static final String STRING_VALUE_FIELD = "stringValue";
private EntityJsonPrinter entityJsonPrinter;
@Setup
public void setup() {
entityJsonPrinter = new EntityJsonPrinter();
}
/**
* Processes Datstore entity into json and then to pojo.
* @throws JsonProcessingException
* @throws JsonMappingException
*/
@ProcessElement
public void processElement(ProcessContext c) throws InvalidProtocolBufferException, JsonProcessingException {
Entity entity = c.element();
String entityJson = entityJsonPrinter.print(entity);
ObjectMapper mapper = new ObjectMapper();
JsonNode rootNode = mapper.readTree(entityJson);
Person person = new Person();
person.setName(rootNode.get(PROPERTIES_FIELD).get("name").get(STRING_VALUE_FIELD).toString().replace("\"", ""));
person.setStatus(rootNode.get(PROPERTIES_FIELD).get("status").get(STRING_VALUE_FIELD).toString().replace("\"", ""));
person.setDob(rootNode.get(PROPERTIES_FIELD).get("dob").get(STRING_VALUE_FIELD).toString().replace("\"", ""));
c.output(person);
}
}Based on the GQL query passed during runtime, the entities are fetched from datastore, converted to json and then to avro as that was my requirement.
Update Entity
java -jar firestore-crud-demo-0.0.1-SNAPSHOT.jar \
--runner=DataflowRunner --project=my-project \
--region=us-east1 --zone=us-east1-b \
--jobName=update-entity-datastore \
--serviceAccount=datastore-crud-demo.iam.gserviceaccount.com \
--subnetwork=https://www.googleapis.com/compute/v1/projects/my-project/regions/us-east1/subnetworks/my-sub-net-001 \
--usePublicIps=false --workerMachineType=n1-standard-1 --numWorkers=1 --maxNumWorkers=3 \
--tempLocation=gs://demo-bucket/firestore_crud_demo/temp \
--datastoreOperation=update \
--datastoreReadGqlQuery="select * from person where name='kevin'" \
--datastoreReadProjectId=my-project \
--datastoreReadNamespace=demo \
--datastoreWriteProjectId=my-project \
--status=success \
--dob=01-02-2021 \pipeline.apply("ReadFromDatastore", DatastoreIO.v1().read().withProjectId(options.getDatastoreReadProjectId()).withLiteralGqlQuery(options.getDatastoreReadGqlQuery()).withNamespace(options.getDatastoreReadNamespace()))
.apply("UpdateEntity", ParDo.of(new UpdateEntity(options.getProcessName(), options.getProcessStatus(), options.getStartDate(), options.getEndDate())))
.apply("WriteToDatastore", DatastoreIO.v1().write().withProjectId(options.getDatastoreWriteProjectId()));public class UpdateEntity extends DoFn<Entity, Entity> {
private static final long serialVersionUID = 100000786887L;
private String status;
private String dob;
public UpdateEntity(String status, String dob) {
this.status = status;
this.dob = dob;
}
@ProcessElement
public void processElement(ProcessContext c) throws InvalidProtocolBufferException {
Entity oldEntity = c.element();
Key key = oldEntity.getKey();
Entity updatedEntity = Entity.newBuilder(oldEntity)
.setKey(key)
.putProperties("status", makeValue(this.status).setExcludeFromIndexes(true).build())
.putProperties("dob", makeValue(this.dob).setExcludeFromIndexes(true).build())
.build();
c.output(updatedEntity);
}
}There is no straight forward method in datastore to update an entity, so first we need to fetch the entities based on the GQL query passed as argument and then update only those entities properties.

Delete Entity
java -jar firestore-crud-demo-0.0.1-SNAPSHOT.jar \
--runner=DataflowRunner --project=my-project --region=us-east1 --zone=us-east1-b \
--jobName=delete-entity-datastore \
--serviceAccount=datastore-crud-demo.iam.gserviceaccount.com \
--subnetwork=https://www.googleapis.com/compute/v1/projects/my-project/regions/us-east1/subnetworks/my-sub-net-001 \
--usePublicIps=false --workerMachineType=n1-standard-1 --numWorkers=1 --maxNumWorkers=3 \
--tempLocation=gs://demo-bucket/firestore_crud_demo/temp \
--datastoreOperation=delete \
--datastoreReadGqlQuery="select * from person where name='kevin'" \
--datastoreReadProjectId=my-project \
--datastoreReadNamespace=demo \
--datastoreWriteProjectId=my-projectpipeline.apply("ReadFromDatastore", DatastoreIO.v1().read().withProjectId(options.getDatastoreReadProjectId()).withLiteralGqlQuery(options.getDatastoreReadGqlQuery()).withNamespace(options.getDatastoreReadNamespace()))
.apply("DeleteFromDatastore", DatastoreIO.v1().deleteEntity().withProjectId(options.getDatastoreWriteProjectId()));There is no straight forward way in datastore to delete an entity, so first we need to fetch the entities based on the GQL query passed as argument and then delete those with the built in deleteEntity method


Comments