Authenticating GKE Applications to Google Cloud Services with Workload Identity
- Vishakh Rameshan
- Mar 14, 2021
- 4 min read

For the applications deployed on to Google Kuberenetes Engine there are different ways in which we can authenticate the application to use the Google Cloud services outside of the kubernetes cluster. The previous approaches of doing this had its downfalls and so has Google introduced something called "Workload Identity".
To understand what is Workload Identity and how it overcomes the pitfalls of the previous approaches, it is good to know what are the other two approaches previously used and what downfalls do they have.
Cluster Node's IAM Service Account
As you know that GKE clusters consists of Compute Engine VMs, all the workloads running in those VMs can use the default compute engine service account to communicate with other google cloud services. This service account is by default created by Google and is recommended to be not altered by adding or removing the roles to it. Even so the problem here is that based on the principle of least privilege, we must segregate the roles given to each applications running on the GKE cluster without which all the application running on the cluster will be using same compute engine service account with all the privileges that comes with it.
Service Account keys as Secrets
This is the most used approach where we download the keys as json file and keep it as a kuberenetes secret or retrieve from Hashicorp vault. The problem here is that the keys being very powerful, if an attacker gets access to the key, he has access to the google cloud services based on the roles assigned to that service account. Even if we go with the principle of least privilege, attacker still has access to whatever smaller the role was assigned to, as the service account keys only expire after every 10 years, so you must perform proper rotation of the keys thus bringing more work to the DevOps or SREs plate.
Workload Identity - New Approach
This approach helps to follow the principle of least privilege, make it easy for application authentication and removes the burden of managing the keys.
Google recommends this approach with the following advantages:-
By enforcing the principle of least privilege, your workloads only have the minimum permissions needed to perform their function. Because you don’t grant broad permissions (like when using the node service account), you reduce the scope of a potential compromise.
Since Google manages the namespace service account credentials for you, the risk of accidental disclosure of credentials through human error is much lower. This also saves you the burden of manually rotating these credentials.
Credentials actually issued to the Workload Identity are only valid for a short time, unlike the 10-year lived service account keys, reducing the blast radius in the event of a compromise.
How can it be achieved?
Workload identity can be achieved as follows :-
1. Enable workload identity on existing cluster with
gcloud container clusters update CLUSTER_NAME \
--workload-pool=PROJECT_ID.svc.id.googor to the new cluster
gcloud container clusters create CLUSTER_NAME \
--workload-pool=PROJECT_ID.svc.id.googBy default, Workload Identity is enabled on GKE Autopilot clusters
When you enable Workload Identity on your GKE cluster, the cluster's workload identity pool will be set to PROJECT_ID.svc.id.goog
2. Migrate applications to Workload Identity
Add a new node pool to the cluster with Workload Identity enabled and manually migrate workloads to that pool. This succeeds only if Workload Identity is enabled on the cluster.
gcloud container node-pools create NODEPOOL_NAME \
--cluster=CLUSTER_NAME \
--workload-metadata=GKE_METADATAThe --workload-metadata=GKE_METADATA is by default enabled for the clusters whose workload identity is enabled.
Update an existing node pool
gcloud container node-pools update NODEPOOL_NAME \
--cluster=CLUSTER_NAME \
--workload-metadata=GKE_METADATA3. Create Namespace for your application
kubectl create namespace K8S_NAMESPACE4. Create Kubernetes Service Account
kubectl create serviceaccount --namespace K8S_NAMESPACE KSA_NAME5. Create Google Service Account or use existing one
6. Use Kubernetes service account created previously for each application or per namespace to use the targeted GCP service account
gcloud iam service-accounts add-iam-policy-binding \
--role roles/iam.workloadIdentityUser \
--member "serviceAccount:[PROJECT_NAME].svc.id.goog[[K8S_NAMESPACE]/[KSA_NAME]]" \
[GSA_NAME]@[PROJECT_NAME].iam.gserviceaccount.com7. Let Kuberenetes service account know which Google Service account to use when the application need to authenticate and use Google services by performing kubectl annotate
kubectl annotate serviceaccount \
--namespace [K8S_NAMESPACE] \
[KSA_NAME] \
iam.gke.io/gcp-service-account=[GSA_NAME]@[PROJECT_NAME].iam.gserviceaccount.comNote:-
GCS_NAME is the GCP service account and PROJECT_NAME is the project id
KSA_NAME is Kuberenetes service account and K8S_NAMESPACE is the Kubernetes Namespace under which the application is deployed
Limitations of Workload Identity
Currently, there is only one fixed workload identity pool per Google Cloud project, PROJECT_ID.svc.id.goog, and it is automatically created for you.
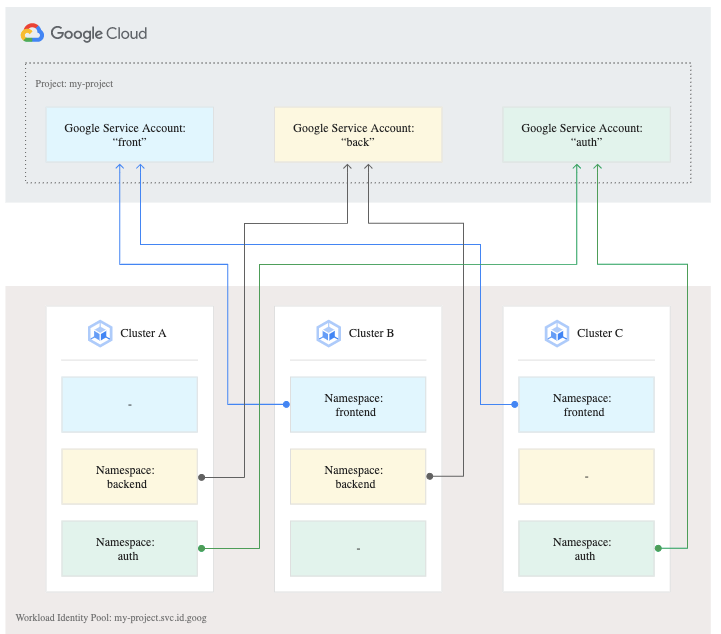
This means that consider the above scenario, if all the cluster belong to same workload identity pool (same GCP project), if cluster C is owned by a separate untrusted team, they too can access the Google Services that Cluster A and Cluster B applications in namespace frontend and auth can access. To overcome this we must segregate the workload identity for the K8s and GCP service account based on Namespace or have the GKE Cluster C on to a different GCP project.
Currently, Workload Identity is not supported when a workload is running in Anthos clusters on VMware.
GKE built-in logging and monitoring agents will continue to use the node's service account.
Workload Identity is not supported on Windows nodes.


Comments